rv8 is a RISC-V simulation suite comprising a high performance x86-64 binary translator, a user mode simulator, a full system emulator, an ELF binary analysis tool and ISA metadata:
- rv-jit - user mode x86-64 binary translator
- rv-sim - user mode system call proxy simulator
- rv-sys - full system emulator with soft MMU
- rv-bin - ELF disassembler and histogram tool
- rv-meta - code and documentation generator
About | Installation | Optimisations | Benchmarks | Logging | Tracing | Histograms | Linux
About
The rv8 simulator suite contains libraries and command line tools for creating instruction opcode maps, C headers and source containing instruction set metadata, instruction decoders, a JIT assembler, LaTeX documentation, a metadata based RISC-V disassembler, a histogram tool for generating statistics on RISC-V ELF executables, a RISC-V proxy syscall simulator, a RISC-V full system emulator that implements the RISC-V 1.9.1 privileged specification and an x86-64 binary translator.
The current version is available at: https://github.com/michaeljclark/rv8

RISC-V to x86-64 binary translator
The rv8 binary translation engine works by interpreting code while profiling it for hot paths. Hot paths are translated on the fly to native code. The translation engine maintains a call stack to allow runtime inlining of hot functions. A jump target cache is used to accelerate returns and indirect calls through function pointers. The translator supports hybrid binary translation and interpretation to handle instructions that do not have native translations. Currently ‘IM’ code is translated and ‘AFD’ is interpreted. The translator supports RVC compressed code.
The rv8 binary translator supports a number of simple optimisations:
- Hybrid interpretation and compilation of hot code paths
- Incremental translation with dynamic trace linking
- Inline caching of function calls in hot code paths
- L1 jump target cache for indirect calls and returns
- Macro-op fusion for common RISC-V instruction sequences
RISC-V full system emulator
The rv8 suite includes a full system emulator that implements the RISC-V privileged ISA with support for interrupts, MMIO (memory mapped input output) devices, a soft MMU (memory management unit) with separate instruction and data TLBs (translation lookaside buffers). The full system emulator has a simple integrated debugger that allows setting breakpoints, single stepping and disassembling instructions as they are executed.
The rv8 full system emulator has the following features:
- RISC-V IMAFD Base plus Privileged ISA (riscv32 and riscv64)
- Simple integrated debug command line interface
- Histograms (registers, instruction and program counter frequency)
- Soft MMU supporting sv32, sv39, sv48 page translation modes
- Abstract MMIO device interface for device emulation
- Extensible interpreter generated from ISA metadata
- Protected address space
RISC-V user mode simulator
The rv8 user mode simulator is a single address space implementation of the RISC-V ISA that implements a subset of the RISC-V Linux syscall ABI (application binary interface) and delegates system calls to the underlying native host operating system. The user mode simulator can run RISC-V Linux binaries on non-Linux operating systems via system call emulation. The current user mode simulator implements a small number of Linux system calls to allow running RISC-V Linux ELF static binaries.
The rv8 user mode simulator has the following features:
- RISC-V IMAFD Base ISA (riscv32 and riscv64)
- Simple integrated debug command line interface
- A small set of emulated Linux system calls for simple file IO
- Extensible interpreter generated from ISA metadata
- Instruction logging mode for tracing program execution
- Shared address space
0x000000000000 - 0x000000000fff(zero)0x000000001000 - 0x7ffdffffffff(guest)0x7ffe00000000 - 0x7fffffffffff(host)
RISC-V instruction set metadata
The rv-bin tool contains a meta-data driven disassembler and
a histogram tool for analysing static register usage and static
instruction usage.
The rv-meta tool is able to generate opcode maps, instruction
decoders, source, headers and instruction set listing LaTeX
from ISA metadata. The following is an example of PDF output:
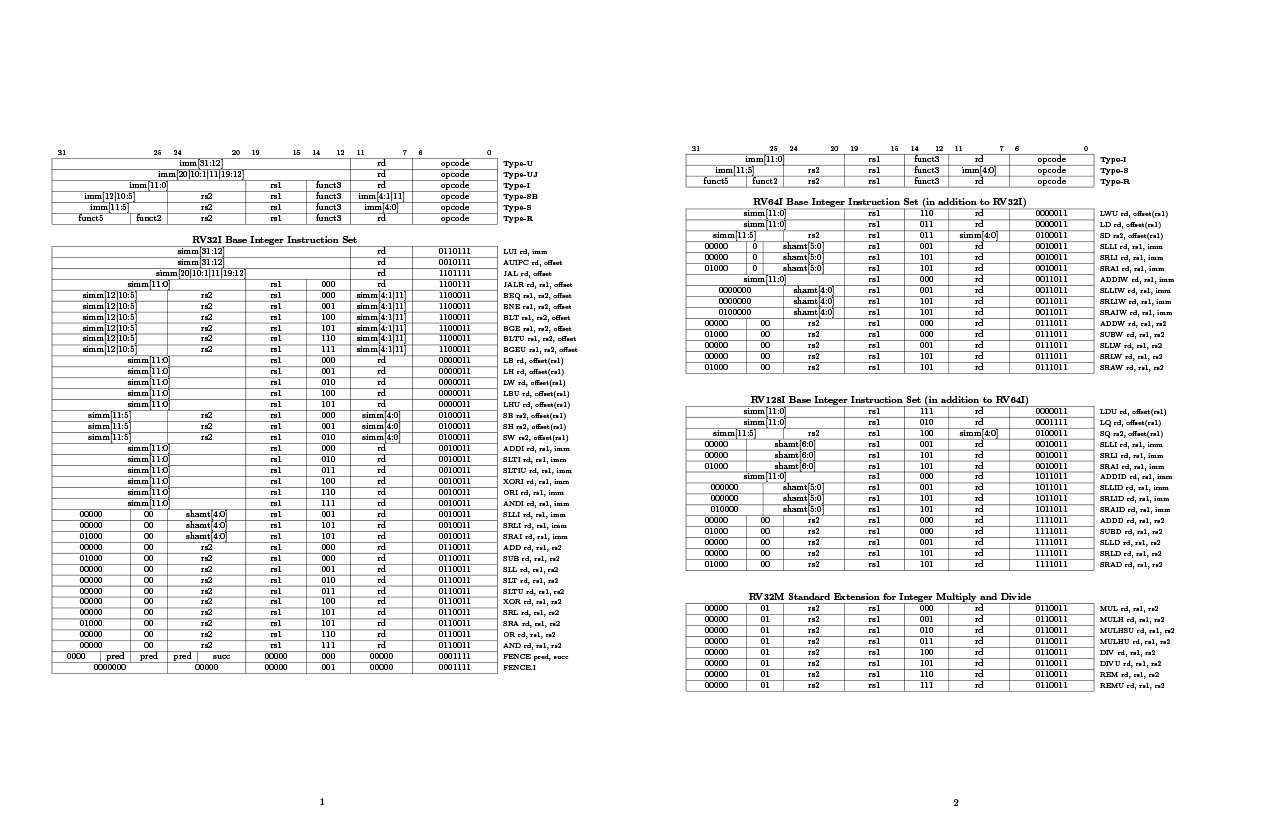
RISC-V instruction set metadata is available here.
The linked page shows an example RISC-V Instruction Set Reference
generated by the rv-meta tool. rv8 has a simple extensible generator
framework that allows reflection on the instruction set metadata to
generate a number of different output formats.
Installation
rv8 supports the following target architecture and host operating system combinations:
- Target
- RV32IMAFDC
- RV64IMAFDC
- Privilged ISA 1.9.1
- Host
- Linux (Debian 9.0 x86-64, Ubuntu 16.04 x86-64, Fedora 25 x86-64) (stable)
- macOS (Sierra 10.11 x86-64) (stable)
- FreeBSD (11 x86-64) (alpha)
Please read the RISC-V toolchain installtion instructions in the riscv-gnu-toolchain repository. To experiment with the RISC-V toolchain online try the RISC-V Compiler Explorer.
Building riscv-gnu-toolchain
$ sudo apt-get install autoconf automake autotools-dev curl \
libmpc-dev libmpfr-dev libgmp-dev gawk build-essential \
bison flex texinfo gperf libtool patchutils bc zlib1g-dev
$ git clone https://github.com/riscv/riscv-gnu-toolchain.git
$ cd riscv-gnu-toolchain
$ git submodule update --init --recursive
$ ./configure --prefix=/opt/riscv/toolchain
$ make
rv8 has minimal external dependencies besides a C++14 compiler,
the C/C++ standard libraries and the asmjit submodule.
- gcc-5.4 or clang-3.4 (Linux minimum)
- gcc-6.3 or clang-3.8 (Linux recommended)
Building rv8
$ git clone https://github.com/michaeljclark/rv8.git
$ cd rv8
$ git submodule update --init --recursive
$ make
$ sudo make install
Running rv8
The riscv64-unknown-elf newlib toolchain is required for building
the rv8 test cases and this build step depends on the RISCV
environment variable.
$ cd rv8
$ export RISCV=/opt/riscv/toolchain
$ make test-build
$ make test-sim
$ make test-sys
$ rv-jit build/riscv64-unknown-elf/bin/test-dhrystone
Optimisations
The rv8 binary translator performs JIT (Just In Time) translation of RISC-V code to X86-64 code. This is a challenging problem for many reasons; with the principle challange due to RISC-V having 31 integer registers while x86-64 has only 16 integer registers.
Register allocation
rv8 solves the register set size problem by using a static register
allocation and spilling registers to memory (L1 cache) (a future
versions may use dynamic register allocator). A significant amount of
performance is lost due to register allocations that take advantage
of the larger number of available registers and less frequent stack
spills. It is not possible for the translator to rearrange memory
and registers for optimal stack spills as memory accesses must be
translated precisely. The additional registers are translated as
x86-64 memory operands (which produce load and store micro-ops)
or in some circumstances, explicit mov instructions.
| RV | x86 | RV | x86 | RV | x86 | RV | x86 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ra | → | rdx | t1 | → | rdi | a2 | → | r10 | a5 | → | r13 | |||
| sp | → | rbx | a0 | → | r8 | a3 | → | r11 | a6 | → | r14 | |||
| t0 | → | rsi | a1 | → | r9 | a4 | → | r12 | a7 | → | r1 |
The remaining unallocated registers are stored in a memory spill
area accessed using the rbp register. e.g. qword [rbp+0xF8]
would be used to access t4.
Translator temporaries
The rv8 translator needs to use several host registers to point to translator internal structures and for use as temporary registers for the emulation of many instructions, for example a store instructions require the use of two temporary registers if both register operands are in the spill area. The translator uses the following x86-64 host registers as temporaries leaving 12 registers available for mapping to RISC-V registers:
rbp- pointer to the register spill area and jump target cachersp- pointer to the host stack to allow procedure callsrax- translator temporary registerrcx- translator temporary register
CISC vs RISC operands
The rv8 translator makes use of CISC memory operands to access registers residing in the memory backed register spill area, which resides in L1 cache. The complex memory operands end up being cracked back into micro-ops in the CISC pipeline however the use of complex memory operands helps increase instruction density, which increases performance due to better use of I$ (instruction cache).
There are many combinations of instruction expansions depending on whether a register is mapped to a live register, is memory backed and whether there are two or three operands. A three operand RISC-V instruction is translated into a move and a destructive two operand x86-64 instruction. Temporary registers are used if both operands are memory backed. The principle is to maintain the densest possible mapping to the x86-64 ISA.
Memory operands are used to access registers in the spill area:

Indirect call acceleration
Indirect calls through function pointers cannot be statically translated as the target address of their translation is not known at the time of translation. rv8 employs a trace cache which is a hashtable of guest program addresses to native code addresses. A full trace cache lookup is relatively slow because it requires saving caller-save registers and calling into C++ code. To accelerate indirect calls through function pointers, a small assembly stub looks up the target address in a sparse 1024 entry direct mapped L1 translation cache, and falls back to a slow translation cache miss path that saves registers and calls into the translator code to populate the L1 translation cache so that the next indirect call can be accelerated.

The direct mapped L1 translation cache is indexed by bits[10:1]
of the guest address. Bit zero can be ignored because RISC-V
instructions must start on a 2-byte boundary
Inline caching
Returns also make use of the L1 translation cache, however a
procedure call made inside of a hot trace can be inlined.
The translator maintains a call stack to keep track of return
addresses. Upon reaching an inlined procedure RET (jalr zero, ra)
instruction, the link register (ra in RISC-V, rdx in
the x86 translation) is compared against the callers known
return address and if it matches, control flow continues
along the return path. In the case that the function is not
inlined, the regular L1 translation cache is used to lookup
the address of the translated code.
An inlined subroutine call needs to test the return address:

Branch tail dynamic linking
The translator performs lazy translation of the source program during tracing and when it reaches branches, it can only link both sides of the branch if there exists an existing translation for the not taken side of the branch. To accelerate branch tail exits, the translator emits a relative branch to a trampoline that returns to the tracer main loop, and the tracer adds the branch to a table of branch fixup addresses indexed by target guest address. If the branch target is hot, once it has been translated, all relative branches that point to tail exit trampolines will be relinked to branch directly to the translated native code.
Macro-op fusion
The rv8 translator implements an optimisation known as macro-op fusion whereby specific patterns of adjacent instructions are translated into a smaller sequence of host instructions. The macro-op fusion pattern matcher has potential to increase performance further with the addition of common patterns. The following is a list of macro-op fusion patterns that are currently implemented in rv8:
AUIPC rs, imm20; ADDI rd, rs1, imm12;- PC-relative address is resolved using a single
MOVinstruction.
- PC-relative address is resolved using a single
AUIPC t0, imm20; JALR ra, imm12(t0);- Target address is constructed using a single
MOVinstruction.
- Target address is constructed using a single
AUIPC ra, imm20; JALR ra, imm12(ra);- Target address register write is elided.
AUIPC rd, imm20; LW rd, imm12(rs1);- Fused into single
MOVwith an immediate addressing mode
- Fused into single
AUIPC rd, imm20; LD rd, imm12(rs1);- Fused into single
MOVwith an immediate addressing mode
- Fused into single
SLLI rd, rs1, 32; SRLI rd, rs1, 32;- Fused into a single
MOVZXinstruction.
- Fused into a single
ADDIW rd, rs1, imm12; SLLI rd, rs1, 32; SRLI rd, rs1, 32;- Fused into 32-bit zero extending
ADDinstruction.
- Fused into 32-bit zero extending
SRLI r1, rs, imm12; SLLI r2, rs, 64 - imm12; OR r1, r1, r2;- Fused into 64-bit
RORwith one residualSHLorSHRtemporary
- Fused into 64-bit
SRLIW r1, rs, imm12; SLLIW r2, rs, 32 - imm12; OR r1, r1, r2;- Fused into 32-bit
RORwith one residualSHLorSHRtemporary
- Fused into 32-bit
A technique known as deoptimisation can be employed to allow elision of temporary registers in macro-op fusion patterns assuming the translator sees the register killed within its translation window. Deoptimisation requires that the optimised translation has an accompanying deoptimisation sequence to fill in elided register values, and this is played back in the case of a fault (device or debug interrupt) so that the visible machine state precisely matches that which the ISA dictates. rv8 does not presently implement deoptimisation, however it may be necessary to allow more sophisticated optimisations.
Sign extension versus zero extension
In addition to the register allocation problem, rv8 has to make sure that 32-bit operations on registers are sign extended instead of zero-extended. The normal behaviour of 32-bit operations on x86-64 is to zero extend bit 31 to bit 63 whereas RISC-V sign extends bit 31 to bit 63. One potential optimisation is lazy sign extension. It may be possible in a future version of the JIT translation engine to elide redundant sign extension operations, however it is important that the register state precisely matches the semantics of the ISA before executing an instruction that may cause a fault e.g. loads and stores.
Example of sign-extended vs zero-extended 32-bit arithmetic on RISC-V and x86-64:

Bit manipulation intrinsics
The bencharks below contain digest algorithms and ciphers which
can take advantage of bit manipulation instructions such as rotate
and bswap. Present day compilers detect rotate and byte swap bitwise
logical operations by matching intermediate representation patterns
that can be lowered directly to bit manipulation instructions such
as ROR, ROL, BSWAP on x86-64. This approach has the benefit
of accelerating code that does not use inline assembly or compiler
builtin functions. RISC-V currently lacks bit manipulation instructions
however there are proposals to add them in the B extension.
The following is a typical byte swap pattern.
- 32-bit integer byteswap pattern (4 constants, 4 shifts, 4 ands, 3 ors)
((rs1 >> 24) & 0x000000ff) | ((rs1 << 8 ) & 0x00ff0000) |
((rs1 >> 8 ) & 0x0000ff00) | ((rs1 << 24) & 0xff000000)
rv8 implements rotate macro-op fusion which can translate two
shift instructions and one OR instructions with the correct
offsets into one shift and one rotate. The rotate macro-op fusion
needs to create the residual temporary register side effects so
that the register file contents are precisely matched, as it can’t
easily prove the residual temporary register is not later used.
Deoptimisation would be required to elide the temporary register.
- 32-bit rotate right or left pattern (2 shifts, 1 or)
(rs1 >> shamt) | (rs1 << (32 - shamt))
- 64-bit rotate right or left pattern (2 shifts, 1 or)
(rs1 >> shamt) | (rs1 << (64 - shamt))
Measurement
A future goal is to quantify the factors that contribute to the performance differences between native x86-64 code and translated RISC-V code, so future benchmarks should measure:
- Sign extension overhead
- Indirect call/return overhead
- Macro-op fusion performance improvement
- Register allocation and spilled register accesses
- Work per instruction (fused and unfused micro-ops)
Benchmarks
The following section contains benchmark runtime and instructions per second results comparing the QEMU and rv8 JIT engines against native x86. This section also contains runtime neutral results comparing total retired RISC-V instructions to x86 micro-ops. The benchmark programs are compiled for aarch64, arm32, riscv64, riscv32, x86-64 and x86-32. See the Benchmarks Results page for the complete result set including optimisation level comparisons, macro-op fusion performance, executable file sizes, dynamic register and instruction usage charts.
Benchmark source
The following sources have been used to run the benchmarks:
- rv8 - https://github.com/michaeljclark/rv8/
- rv8-bench - https://github.com/michaeljclark/rv8-bench/
- qemu-riscv - https://github.com/riscv/riscv-qemu/
- musl-riscv-toolchain - https://github.com/michaeljclark/musl-riscv-toolchain/
Benchmark metrics
The following benchmark metrics have been plotted and tabulated:
Benchmark details
The rv8-bench benchmark suite contains the following test programs:
| Benchmark | Type | Description |
|---|---|---|
| aes | crypto | encrypt, decrypt and compare 30MiB of data |
| bigint | numeric | compute 23 ^ 111121 and count base 10 digits |
| dhrystone | synthetic | synthetic integer workload |
| miniz | compression | compress, decompress and compare 8MiB of data |
| norx | crypto | encrypt, decrypt and compare 30MiB of data |
| primes | numeric | calculate largest prime number below 33333333 |
| qsort | sorting | sort array containing 50 million items |
| sha512 | digest | calculate SHA-512 hash of 64MiB of data |
Compiler details
The following compiler architectures, versions, compile options and runtime libraries are used to run the benchmarks:
| Architecture | Compiler | C Library | Compile options |
|---|---|---|---|
| x86-32 | GCC 7.1.0 | musl libc | '-O3', '-O2' and '-Os' |
| x86-64 | GCC 7.1.0 | musl libc | '-O3', '-O2' and '-Os' |
| riscv32 | GCC 7.1.0 | musl libc | '-O3', '-O2' and '-Os' |
| riscv64 | GCC 7.1.0 | musl libc | '-O3', '-O2' and '-Os' |
| arm32 | GCC 7.2.0 | musl libc | '-O3', '-O2' and '-Os' |
| aarch64 | GCC 7.1.0 | musl libc | '-O3', '-O2' and '-Os' |
Measurement details
- Dynamic instruction counts are measured using
rv-sim -E - Benchmarks are run 20 times and the best result is taken
- All programs are compiled as position independent executables (
-fPIE) - Host: Intel® 6th-gen Core™ i7-5557U Broadwell (3.10-3.40GHz, 4MB cache)
- x86-64 μops measured with
perf stat -e cycles,instructions,r1b1,r10e,r2c2,r1c2 <cmd>
Runtimes
Runtime results comparing qemu, rv8 and native x86:

Figure 1: Benchmark runtimes -O3 64-bit
Runtime 64-bit -O3 (seconds)
| program | qemu-aarch64 | qemu-riscv64 | rv8-riscv64 | native-x86-64 |
|---|---|---|---|---|
| aes | 1.31 | 2.16 | 1.49 | 0.32 |
| bigint | 1.38 | 1.08 | 0.71 | 0.38 |
| dhrystone | 0.98 | 0.57 | 0.20 | 0.10 |
| miniz | 2.66 | 2.21 | 1.53 | 0.77 |
| norx | 0.60 | 1.17 | 0.99 | 0.22 |
| primes | 2.09 | 1.26 | 0.65 | 0.60 |
| qsort | 7.38 | 4.76 | 1.21 | 0.64 |
| sha512 | 0.64 | 1.24 | 0.81 | 0.24 |
| (Sum) | 17.04 | 14.45 | 7.59 | 3.27 |
Performance Ratio 64-bit -O3 (smaller is better)
| program | qemu-aarch64 | qemu-riscv64 | rv8-riscv64 | native-x86-64 |
|---|---|---|---|---|
| aes | 4.12 | 6.76 | 4.68 | 1.00 |
| bigint | 3.62 | 2.83 | 1.85 | 1.00 |
| dhrystone | 9.96 | 5.87 | 2.03 | 1.00 |
| miniz | 3.46 | 2.86 | 1.99 | 1.00 |
| norx | 2.73 | 5.33 | 4.51 | 1.00 |
| primes | 3.49 | 2.11 | 1.09 | 1.00 |
| qsort | 11.55 | 7.46 | 1.90 | 1.00 |
| sha512 | 2.66 | 5.13 | 3.36 | 1.00 |
| (Geomean) | 4.44 | 4.39 | 2.40 | 1.00 |

Figure 2: Benchmark runtimes -O2 64-bit
Runtime 64-bit -O2 (seconds)
| program | qemu-aarch64 | qemu-riscv64 | rv8-riscv64 | native-x86-64 |
|---|---|---|---|---|
| aes | 1.32 | 2.18 | 1.49 | 0.32 |
| bigint | 1.34 | 1.03 | 1.44 | 0.38 |
| dhrystone | 1.77 | 1.06 | 0.23 | 0.12 |
| miniz | 2.72 | 2.22 | 1.52 | 0.77 |
| norx | 0.66 | 1.16 | 1.08 | 0.22 |
| primes | 2.11 | 1.25 | 0.66 | 0.59 |
| qsort | 7.35 | 4.74 | 1.19 | 0.62 |
| sha512 | 0.68 | 1.32 | 0.96 | 0.24 |
| (Sum) | 17.95 | 14.96 | 8.57 | 3.26 |
Performance Ratio 64-bit -O2 (smaller is better)
| program | qemu-aarch64 | qemu-riscv64 | rv8-riscv64 | native-x86-64 |
|---|---|---|---|---|
| aes | 4.13 | 6.84 | 4.68 | 1.00 |
| bigint | 3.51 | 2.70 | 3.76 | 1.00 |
| dhrystone | 14.73 | 8.81 | 1.95 | 1.00 |
| miniz | 3.52 | 2.87 | 1.96 | 1.00 |
| norx | 2.94 | 5.20 | 4.81 | 1.00 |
| primes | 3.58 | 2.13 | 1.12 | 1.00 |
| qsort | 11.79 | 7.60 | 1.91 | 1.00 |
| sha512 | 2.80 | 5.45 | 3.96 | 1.00 |
| (Geomean) | 4.75 | 4.64 | 2.69 | 1.00 |

Figure 3: Benchmark runtimes -Os 64-bit
Runtime 64-bit -Os (seconds)
| program | qemu-aarch64 | qemu-riscv64 | rv8-riscv64 | native-x86-64 |
|---|---|---|---|---|
| aes | 1.22 | 1.91 | 1.26 | 0.37 |
| bigint | 1.60 | 1.40 | 2.85 | 0.38 |
| dhrystone | 5.42 | 2.59 | 1.28 | 0.39 |
| miniz | 2.74 | 2.24 | 1.73 | 0.83 |
| norx | 1.58 | 1.53 | 0.96 | 0.24 |
| primes | 1.97 | 1.23 | 0.74 | 0.59 |
| qsort | 7.99 | 5.27 | 0.90 | 0.66 |
| sha512 | 0.64 | 1.14 | 0.67 | 0.25 |
| (Sum) | 23.16 | 17.31 | 10.39 | 3.71 |
Performance Ratio 64-bit -Os (smaller is better)
| program | qemu-aarch64 | qemu-riscv64 | rv8-riscv64 | native-x86-64 |
|---|---|---|---|---|
| aes | 3.29 | 5.16 | 3.39 | 1.00 |
| bigint | 4.22 | 3.70 | 7.53 | 1.00 |
| dhrystone | 13.97 | 6.66 | 3.30 | 1.00 |
| miniz | 3.30 | 2.70 | 2.09 | 1.00 |
| norx | 6.59 | 6.36 | 4.00 | 1.00 |
| primes | 3.31 | 2.07 | 1.25 | 1.00 |
| qsort | 12.20 | 8.05 | 1.37 | 1.00 |
| sha512 | 2.56 | 4.58 | 2.68 | 1.00 |
| (Geomean) | 5.07 | 4.49 | 2.75 | 1.00 |

Figure 4: Benchmark runtimes -O3 32-bit
Runtime 32-bit -O3 (seconds)
| program | qemu-arm32 | qemu-riscv32 | rv8-riscv32 | native-x86-32 |
|---|---|---|---|---|
| aes | 1.70 | 1.89 | 1.47 | 0.48 |
| bigint | 2.98 | 1.37 | 1.41 | 0.88 |
| dhrystone | 1.17 | 1.11 | 0.39 | 0.28 |
| miniz | 2.99 | 2.17 | 1.41 | 0.88 |
| norx | 0.77 | 0.77 | 0.78 | 0.26 |
| primes | 4.20 | 2.34 | 1.89 | 1.51 |
| qsort | 8.39 | 4.56 | 1.15 | 0.70 |
| sha512 | 3.82 | 2.91 | 1.92 | 0.63 |
| (Sum) | 26.02 | 17.12 | 10.42 | 5.62 |
Performance Ratio 32-bit -O3 (smaller is better)
| program | qemu-arm32 | qemu-riscv32 | rv8-riscv32 | native-x86-32 |
|---|---|---|---|---|
| aes | 3.56 | 3.97 | 3.09 | 1.00 |
| bigint | 3.39 | 1.56 | 1.61 | 1.00 |
| dhrystone | 4.13 | 3.91 | 1.37 | 1.00 |
| miniz | 3.40 | 2.47 | 1.60 | 1.00 |
| norx | 2.98 | 2.96 | 3.00 | 1.00 |
| primes | 2.79 | 1.55 | 1.25 | 1.00 |
| qsort | 12.04 | 6.54 | 1.65 | 1.00 |
| sha512 | 6.04 | 4.60 | 3.04 | 1.00 |
| (Geomean) | 4.23 | 3.09 | 1.95 | 1.00 |

Figure 5: Benchmark runtimes -O2 32-bit
Runtime 32-bit -O2 (seconds)
| program | qemu-arm32 | qemu-riscv32 | rv8-riscv32 | native-x86-32 |
|---|---|---|---|---|
| aes | 1.73 | 1.88 | 1.41 | 0.48 |
| bigint | 2.73 | 1.46 | 1.76 | 0.85 |
| dhrystone | 2.19 | 1.80 | 0.41 | 0.36 |
| miniz | 2.98 | 2.16 | 1.36 | 0.88 |
| norx | 0.84 | 0.78 | 0.83 | 0.27 |
| primes | 4.32 | 2.31 | 1.91 | 1.54 |
| qsort | 10.53 | 4.55 | 1.16 | 0.68 |
| sha512 | 3.78 | 3.95 | 2.19 | 0.57 |
| (Sum) | 29.10 | 18.89 | 11.03 | 5.63 |
Performance Ratio 32-bit -O2 (smaller is better)
| program | qemu-arm32 | qemu-riscv32 | rv8-riscv32 | native-x86-32 |
|---|---|---|---|---|
| aes | 3.59 | 3.92 | 2.93 | 1.00 |
| bigint | 3.19 | 1.71 | 2.06 | 1.00 |
| dhrystone | 6.11 | 5.02 | 1.13 | 1.00 |
| miniz | 3.39 | 2.46 | 1.54 | 1.00 |
| norx | 3.10 | 2.87 | 3.04 | 1.00 |
| primes | 2.81 | 1.50 | 1.24 | 1.00 |
| qsort | 15.44 | 6.67 | 1.70 | 1.00 |
| sha512 | 6.64 | 6.92 | 3.84 | 1.00 |
| (Geomean) | 4.63 | 3.37 | 2.00 | 1.00 |

Figure 6: Benchmark runtimes -Os 32-bit
Runtime 32-bit -Os (seconds)
| program | qemu-arm32 | qemu-riscv32 | rv8-riscv32 | native-x86-32 |
|---|---|---|---|---|
| aes | 1.62 | 1.57 | 1.13 | 0.50 |
| bigint | 3.62 | 1.80 | 3.21 | 1.02 |
| dhrystone | 4.71 | 2.31 | 1.43 | 0.58 |
| miniz | 3.06 | 2.20 | 1.56 | 1.26 |
| norx | 1.38 | 1.18 | 1.00 | 0.32 |
| primes | 4.46 | 2.20 | 2.74 | 1.38 |
| qsort | 8.70 | 5.01 | 0.81 | 0.77 |
| sha512 | 3.52 | 2.69 | 2.20 | 0.79 |
| (Sum) | 31.07 | 18.96 | 14.08 | 6.62 |
Performance Ratio 32-bit -Os (smaller is better)
| program | qemu-arm32 | qemu-riscv32 | rv8-riscv32 | native-x86-32 |
|---|---|---|---|---|
| aes | 3.24 | 3.15 | 2.26 | 1.00 |
| bigint | 3.55 | 1.76 | 3.14 | 1.00 |
| dhrystone | 8.14 | 4.00 | 2.48 | 1.00 |
| miniz | 2.43 | 1.74 | 1.24 | 1.00 |
| norx | 4.32 | 3.70 | 3.12 | 1.00 |
| primes | 3.22 | 1.59 | 1.98 | 1.00 |
| qsort | 11.24 | 6.47 | 1.05 | 1.00 |
| sha512 | 4.47 | 3.41 | 2.78 | 1.00 |
| (Geomean) | 4.47 | 2.90 | 2.11 | 1.00 |
Instructions Per Second
Instructions per second in millions comparing qemu, rv8 and native x86:

Figure 5: Millions of Instructions Per Second -O3 64-bit
Instructions per second (MIPS) qemu, rv8 and native 64-bit -O3
| program | qemu-riscv64-mips | rv8-riscv64-mips | native-x86-mips |
|---|---|---|---|
| aes | 2414 | 3395 | 11035 |
| bigint | 3738 | 5712 | 10557 |
| dhrystone | 1843 | 5274 | 8369 |
| miniz | 2625 | 3622 | 5530 |
| norx | 2223 | 2167 | 9112 |
| primes | 2438 | 4421 | 6100 |
| qsort | 644 | 2518 | 5780 |
| sha512 | 2982 | 4556 | 12177 |
| (Geomean) | 2149 | 3769 | 8232 |

Figure 6: Millions of Instructions Per Second -Os 64-bit
Instructions per second (MIPS) qemu, rv8 and native 64-bit -Os
| program | qemu-riscv64-mips | rv8-riscv64-mips | native-x86-mips |
|---|---|---|---|
| aes | 2655 | 3879 | 10072 |
| bigint | 3973 | 1955 | 12873 |
| dhrystone | 1250 | 2462 | 9073 |
| miniz | 2650 | 3427 | 5052 |
| norx | 1817 | 2439 | 8852 |
| primes | 2226 | 3555 | 6101 |
| qsort | 572 | 3340 | 6063 |
| sha512 | 3269 | 5567 | 12206 |
| (Geomean) | 2008 | 3175 | 8355 |

Figure 7: Millions of Instructions Per Second -O3 32-bit
Instructions per second (MIPS) qemu, rv8 and native 32-bit -O3
| program | qemu-riscv32-mips | rv8-riscv32-mips | native-x86-mips |
|---|---|---|---|
| aes | 2442 | 2851 | 9634 |
| bigint | 3964 | 3835 | 9780 |
| dhrystone | 1998 | 5667 | 3747 |
| miniz | 2195 | 3379 | 4988 |
| norx | 2824 | 2554 | 9146 |
| primes | 3039 | 3652 | 6368 |
| qsort | 671 | 2658 | 6259 |
| sha512 | 2773 | 3671 | 11074 |
| (Geomean) | 2259 | 3428 | 7186 |

Figure 8: Millions of Instructions Per Second -Os 32-bit
Instructions per second (MIPS) qemu, rv8 and native 32-bit -Os
| program | qemu-riscv32-mips | rv8-riscv32-mips | native-x86-mips |
|---|---|---|---|
| aes | 2832 | 3565 | 9472 |
| bigint | 3856 | 2166 | 9817 |
| dhrystone | 1435 | 2345 | 8479 |
| miniz | 2177 | 3062 | 4171 |
| norx | 1965 | 1970 | 8129 |
| primes | 2928 | 2355 | 7105 |
| qsort | 576 | 3528 | 5892 |
| sha512 | 2901 | 3131 | 8396 |
| (Geomean) | 2063 | 2702 | 7441 |
Logging
rv-sim and rv-sys support the ability to log instructions
(--log-instructions), register values (--log-operands) and
rv-sys can log page table walks (--log-pagewalks).
Sample output from rv-sim with the --log-instructions option
$ rv-sim -l build/riscv64-unknown-elf/bin/hello-world-pcrel
0000000000000000000 core-0 :0000000000010078 (4501 ) mv a0, zero
0000000000000000001 core-0 :000000000001007a (00000597) auipc a1, pc + 0
0000000000000000002 core-0 :000000000001007e (02658593) addi a1, a1, 38
0000000000000000003 core-0 :0000000000010082 (4631 ) addi a2, zero, 12
0000000000000000004 core-0 :0000000000010084 (4681 ) mv a3, zero
0000000000000000005 core-0 :0000000000010086 (04000893) addi a7, zero, 64
Hello World
0000000000000000006 core-0 :000000000001008a (00000073) ecall
0000000000000000007 core-0 :000000000001008e (4501 ) mv a0, zero
0000000000000000008 core-0 :0000000000010090 (4581 ) mv a1, zero
0000000000000000009 core-0 :0000000000010092 (4601 ) mv a2, zero
0000000000000000010 core-0 :0000000000010094 (4681 ) mv a3, zero
0000000000000000011 core-0 :0000000000010096 (05d00893) addi a7, zero, 93
Tracing
The rv-jit program supports the ability to log RISC-V instructions
along with the dynamically translated x86-64 assembly and machine code
(--log-jit-trace). This mode is useful for JIT translation debugging
and optimisation analysis.
Sample output from rv-jit with the --log-jit-trace option
# 0x0000000000103d70 addi a0, zero, 1
mov r8, 1 ; 41B801000000
L3:
# 0x0000000000103d74 slli a0, a0, 28
shl r8, 1C ; 49C1E01C
L4:
# 0x0000000000103d78 addi a1, zero, -1
mov r9, FFFFFFFFFFFFFFFF ; 49C7C1FFFFFFFF
L5:
# 0x0000000000103d7c sb a1, 0(a0)
rex mov byte [r8], r9b ; 458808
L6:
# 0x0000000000103d80 lbu a2, 0(a0)
movzx r10d, byte [r8] ; 450FB610
L7:
Histograms
The rv-sim and rv-sys programs support the ability to record and
print histograms. Program counter frequency (--pc-usage-histogram),
dynamic instruction frequency (--instruction-usage-histogram) and
dynamic register usage (--register-usage-histogram) is supported.
The rv-bin program via the histogram subcommand has the ability
to print static instruction frequency and static register usage.
Sample output from rv-sim with the --register-usage-histogram
and --instruction-usage-histogram options
$ rv-sim --register-usage-histogram \
--instruction-usage-histogram \
build/riscv64-unknown-elf/bin/test-aes
integer register file
~~~~~~~~~~~~~~~~~~~~~
ra :0x00000000000197a4
sp :0x000000007fffff68 gp :0x0000000000020b18
tp :0xe87f5200d8d3e2fd t0 :0x0000000000011808
t1 :0x0000000000040000 t2 :0x000000000000035c
s0 :0x0000000000000000 s1 :0x0e9e1c7894d54be1
a0 :0x0000000000000000 a1 :0x0000000000000000
a2 :0x0000000000000000 a3 :0x0000000000000000
a4 :0x0000000000000000 a5 :0x0000000000000000
a6 :0x0000000006021440 a7 :0x000000000000005d
s2 :0x94a7319b493ab93c s3 :0xb643788d224af6fb
s4 :0x7269d597ce6e1df9 s5 :0x5f9113739f9b0d72
s6 :0x404c0e868734cf0c s7 :0x2aea8c1ef338fa59
s8 :0xff41772b6673e771 s9 :0x7a5a4806d4a6fe41
s10 :0x0a595462adddb5a8 s11 :0xda895865c86e2f07
t3 :0x0000000000000001 t4 :0x0000000000000000
t5 :0x0000000004000000 t6 :0x0000000000000000
control and status registers
~~~~~~~~~~~~~~~~~~~~~~~~~~~~
instret : 5148514055 time :0x000290f90f8a9e3b
pc :0x000000000001944e fcsr :0x00000000
register usage histogram
~~~~~~~~~~~~~~~~~~~~~~~~
1. a5 15.11% [1769998250] #######################################
2. a2 13.35% [1564476600] ##################################
3. a7 10.03% [1174405210] #########################
4. a4 9.15% [1071646586] #######################
5. a6 7.50% [878706827] ###################
6. t4 5.12% [599785551] #############
7. t6 4.91% [574619648] ############
8. t1 4.65% [545259607] ############
9. a1 2.26% [264241924] #####
10. s1 2.15% [251658621] #####
11. s0 2.02% [236978689] #####
12. s8 2.01% [234881068] #####
13. t5 1.79% [209715245] ####
14. t0 1.68% [197132294] ####
15. s2 1.63% [190840979] ####
16. a0 1.61% [188744347] ####
17. s4 1.50% [176160835] ###
18. s5 1.50% [176160833] ###
19. s3 1.47% [171966617] ###
20. sp 1.43% [167773141] ###
21. s6 1.43% [167772235] ###
22. t3 1.43% [167772225] ###
23. s7 1.43% [167772223] ###
24. t2 1.36% [159383552] ###
25. zero 0.86% [100664377] ##
26. s9 0.75% [88080392 ] #
27. a3 0.68% [79693333 ] #
28. s11 0.68% [79691785 ] #
29. s10 0.43% [50331663 ] #
30. ra 0.07% [8388996 ]
31. gp 0.00% [90 ]
instruction usage histogram
~~~~~~~~~~~~~~~~~~~~~~~~~~~
1. lw 16.37% [843055543] #######################################
2. xor 13.85% [713031972] ################################
3. add 13.69% [704643870] ################################
4. slli 13.20% [679477645] ###############################
5. srliw 10.75% [553648296] #########################
6. andi 9.94% [511705332] #######################
7. srli 3.05% [157286473] #######
8. lbu 2.93% [150995155] ######
9. addi 2.69% [138412722] ######
10. addiw 2.44% [125829177] #####
11. sd 1.79% [92275184 ] ####
12. sb 1.47% [75497501 ] ###
13. jal 1.14% [58720476 ] ##
14. beq 1.06% [54526059 ] ##
15. ld 0.98% [50332182 ] ##
16. and 0.98% [50331715 ] ##
17. slliw 0.98% [50331682 ] ##
18. bne 0.90% [46137534 ] ##
19. or 0.65% [33554442 ] #
20. auipc 0.41% [20971539 ]
21. lui 0.24% [12583002 ]
22. mulw 0.16% [8388608 ]
23. lwu 0.16% [8388608 ]
24. jalr 0.08% [4194443 ]
25. sraiw 0.08% [4194314 ]
26. sw 0.00% [213 ]
27. bltu 0.00% [78 ]
28. bge 0.00% [39 ]
29. blt 0.00% [33 ]
30. bgeu 0.00% [33 ]
31. sub 0.00% [29 ]
...
Linux
This section describes how to build and boot a Linux image in the full system emulator.
Please read the RISC-V toolchain installation instructions in the
riscv-gnu-toolchain
repository. The riscv64-unknown-elf newlib toolchain is required
for building the rv8 test cases and the riscv64-unknown-linux-gnu
glibc toolchain is required for building busybox which is used to
create the Linux image that runs in the full system emulator.
The toolchain script will download any required dependencies.
Building riscv-gnu-toolchain for linux
$ cd riscv-gnu-toolchain
$ make linux
The linux build script will download any required dependencies.
Building linux, busybox and bbl-lite
$ cd rv8
$ export RISCV=/opt/riscv/toolchain
$ export PATH=${PATH}:${RISCV}/bin
$ make linux
To start linux, we execute bbl (the Berkeley Boot Loader) which
performs early machine set up and then passes control to an
embedded linux kernel. After kernel initialisation, busybox is
then executed from the initramfs as pid 1 (init). The linux image
and the initramfs are combined together and linked into bbl as
the boot payload.
Running the full system emulator
$ rv-sys build/riscv64-unknown-elf/bin/bbl
vvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvv
vvvvvvvvvvvvvvvvvvvvvvvvvvvv
rrrrrrrrrrrrr vvvvvvvvvvvvvvvvvvvvvvvvvv
rrrrrrrrrrrrrrrr vvvvvvvvvvvvvvvvvvvvvvvv
rrrrrrrrrrrrrrrrrr vvvvvvvvvvvvvvvvvvvvvvvv
rrrrrrrrrrrrrrrrrr vvvvvvvvvvvvvvvvvvvvvvvv
rrrrrrrrrrrrrrrrrr vvvvvvvvvvvvvvvvvvvvvvvv
rrrrrrrrrrrrrrrr vvvvvvvvvvvvvvvvvvvvvv
rrrrrrrrrrrrr vvvvvvvvvvvvvvvvvvvvvv
rr vvvvvvvvvvvvvvvvvvvvvv
rr vvvvvvvvvvvvvvvvvvvvvvvv rr
rrrr vvvvvvvvvvvvvvvvvvvvvvvvvv rrrr
rrrrrr vvvvvvvvvvvvvvvvvvvvvv rrrrrr
rrrrrrrr vvvvvvvvvvvvvvvvvv rrrrrrrr
rrrrrrrrrr vvvvvvvvvvvvvv rrrrrrrrrr
rrrrrrrrrrrr vvvvvvvvvv rrrrrrrrrrrr
rrrrrrrrrrrrrr vvvvvv rrrrrrrrrrrrrr
rrrrrrrrrrrrrrrr vv rrrrrrrrrrrrrrrr
rrrrrrrrrrrrrrrrrr rrrrrrrrrrrrrrrrrr
rrrrrrrrrrrrrrrrrrrr rrrrrrrrrrrrrrrrrrrr
rrrrrrrrrrrrrrrrrrrrrr rrrrrrrrrrrrrrrrrrrrrr
INSTRUCTION SETS WANT TO BE FREE
[ 0.000000] Linux version 4.6.2-00044-g250754b-dirty (mclark@minty) (gcc version 7.1.1 20170509 (GCC) ) #2 Sat Jul 1 22:42:14 NZST 2017
[ 0.000000] bootconsole [early0] enabled
[ 0.000000] Available physical memory: 1020MB
[ 0.000000] Initial ramdisk at: 0xffffffff800100b0 (261728 bytes)
[ 0.000000] Zone ranges:
[ 0.000000] Normal [mem 0x0000000080400000-0x00000000bfffffff]
[ 0.000000] Movable zone start for each node
[ 0.000000] Early memory node ranges
[ 0.000000] node 0: [mem 0x0000000080400000-0x00000000bfffffff]
[ 0.000000] Initmem setup node 0 [mem 0x0000000080400000-0x00000000bfffffff]
[ 0.000000] Built 1 zonelists in Zone order, mobility grouping on. Total pages: 257550
[ 0.000000] Kernel command line: earlyprintk=sbi-console rdinit=/sbin/init
[ 0.000000] PID hash table entries: 4096 (order: 3, 32768 bytes)
[ 0.000000] Dentry cache hash table entries: 131072 (order: 8, 1048576 bytes)
[ 0.000000] Inode-cache hash table entries: 65536 (order: 7, 524288 bytes)
[ 0.000000] Sorting __ex_table...
[ 0.000000] Memory: 1025684K/1044480K available (1701K kernel code, 125K rwdata, 488K rodata, 324K init, 230K bss, 18796K reserved, 0K cma-reserved)
[ 0.000000] SLUB: HWalign=64, Order=0-3, MinObjects=0, CPUs=1, Nodes=1
[ 0.000000] NR_IRQS:0 nr_irqs:0 0
[ 0.000000] clocksource: riscv_clocksource: mask: 0xffffffff max_cycles: 0xffffffff, max_idle_ns: 191126044627 ns
[ 0.000000] Calibrating delay loop (skipped), value calculated using timer frequency.. 20.00 BogoMIPS (lpj=100000)
[ 0.000000] pid_max: default: 32768 minimum: 301
[ 0.010000] Mount-cache hash table entries: 2048 (order: 2, 16384 bytes)
[ 0.010000] Mountpoint-cache hash table entries: 2048 (order: 2, 16384 bytes)
[ 0.010000] devtmpfs: initialized
[ 0.010000] clocksource: jiffies: mask: 0xffffffff max_cycles: 0xffffffff, max_idle_ns: 19112604462750000 ns
[ 0.010000] NET: Registered protocol family 16
[ 0.010000] clocksource: Switched to clocksource riscv_clocksource
[ 0.010000] NET: Registered protocol family 2
[ 0.010000] TCP established hash table entries: 8192 (order: 4, 65536 bytes)
[ 0.010000] TCP bind hash table entries: 8192 (order: 4, 65536 bytes)
[ 0.010000] TCP: Hash tables configured (established 8192 bind 8192)
[ 0.010000] UDP hash table entries: 512 (order: 2, 16384 bytes)
[ 0.010000] UDP-Lite hash table entries: 512 (order: 2, 16384 bytes)
[ 0.010000] NET: Registered protocol family 1
[ 0.010000] Unpacking initramfs...
[ 0.010000] console [sbi_console0] enabled
[ 0.010000] console [sbi_console0] enabled
[ 0.010000] bootconsole [early0] disabled
[ 0.010000] bootconsole [early0] disabled
[ 0.010000] futex hash table entries: 256 (order: 0, 6144 bytes)
[ 0.010000] workingset: timestamp_bits=61 max_order=18 bucket_order=0
[ 0.010000] 9p: Installing v9fs 9p2000 file system support
[ 0.010000] io scheduler noop registered
[ 0.010000] io scheduler cfq registered (default)
[ 0.010000] 9pnet: Installing 9P2000 support
[ 0.010000] Freeing unused kernel memory: 324K (ffffffff80000000 - ffffffff80051000)
[ 0.010000] This architecture does not have kernel memory protection.
BusyBox v1.26.1 (2017-06-30 16:46:44 NZST) built-in shell (ash)
Enter 'help' for a list of built-in commands.
/ #